Editorial disclosure: I run affiliate operations at Datify. The case studies we read every week come in through publisher onboarding, payout-tier requests, and Slack DMs. The opinions here are mine. No vendor, network or tracker paid for placement in this article; the four public examples we dissect are picked because they sit on a credibility spectrum we use internally, not because anyone asked us to feature them.
A dating affiliate case study is a published account of how an operator drove paid traffic to a dating CPA, smartlink, or revshare offer and what it returned net of scrub, refunds, and infrastructure. In 2026 three flavours circulate — operator follow-alongs on closed forums, vendor-published “success” posts on ad-network blogs, and network partner spotlights — and only the first is intermittently credible. This guide is the operator-grade rubric for reading, running, and writing them, with four public examples scored against the rubric.
Key takeaways
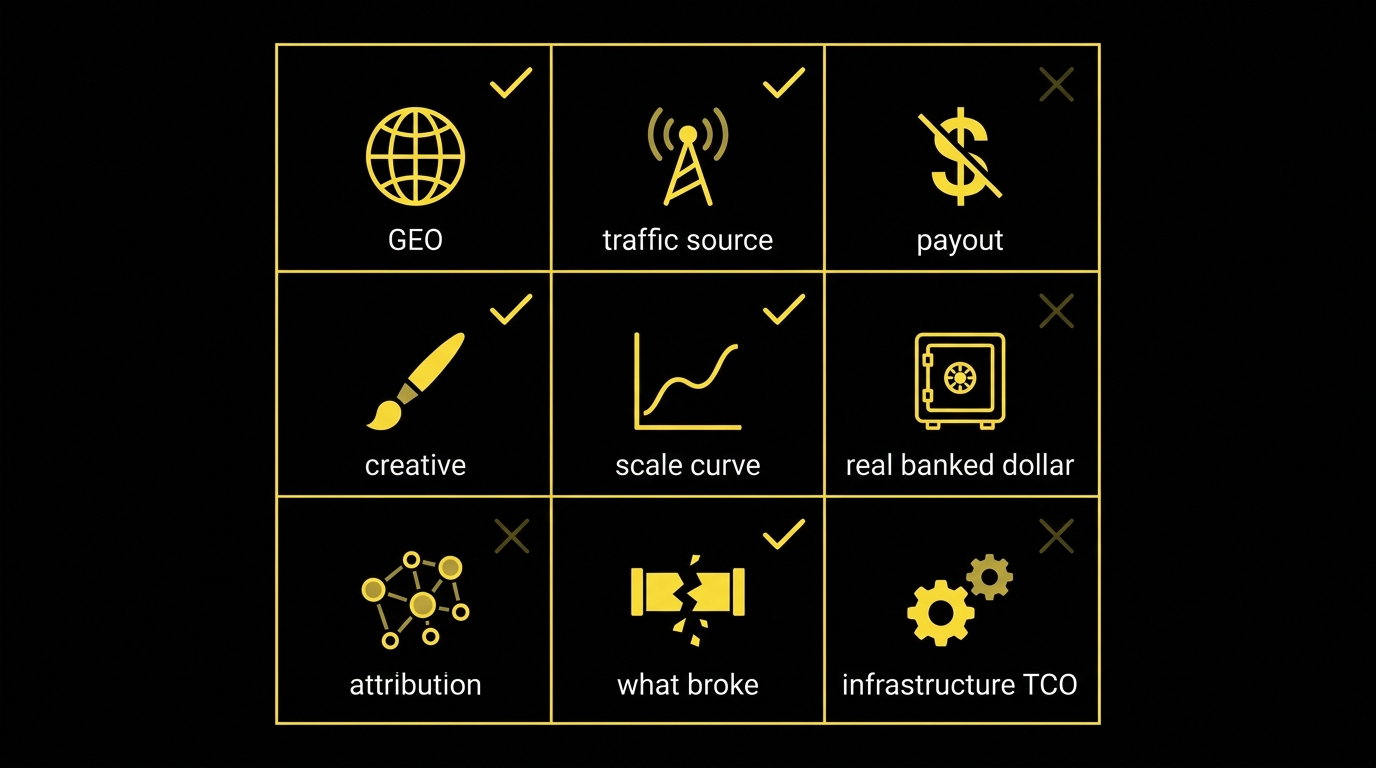
- A credible case study discloses GEO + sub-GEO, traffic source + zone, payout model + realized scrub, scale curve, attribution model, what broke, creative angle, infrastructure TCO, and date range. Most public posts disclose three of nine. Vendor-laundered posts disclose two.
- The biggest source of fake-looking numbers in 2026 is the gap between ratecard and realized eCPM after the advertiser’s monthly scrub — a gap most public case studies do not even acknowledge.
- A “+557% ROI” headline on $33 of spend is structurally a lottery ticket, not a strategy; one such 2024 thread we dissect below was later flagged by forum moderation for multi-account abuse and is still cited as inspiration in 2026 newsletters.
- At Datify, a supplied case study is a three-minute interview filter for whether the publisher talks like an operator. It is not a credit-extension input — every new publisher ramps through the same payout-tier gates regardless of claimed prior earnings elsewhere.
What actually counts as a dating affiliate case study in 2026?
Earlier this year I sat in on a call where a publisher pitched us a four-figure-per-day BR mainstream-dating “success story” pulled from a tracker vendor’s marketing blog. The numbers were rounded, the GEO was “Tier-2”, the traffic source was the tracker vendor’s preferred ad-network partner. Three months later the same case study, lightly reworded, showed up on a different vendor’s blog under a different “operator” handle. That moment is why this article exists.
The three artefacts circulating under the “case study” label are not equivalent. Operator follow-alongs on closed forums — affLIFT, AffiliateFix, STM Forum, BlackHatWorld’s CPA sub-forum — are written for peers who will ask follow-up questions, so the author has reputational skin in the game. Vendor-published “success” posts double as ads for the platform hosting them and we treat them as marketing collateral, not evidence. Network partner spotlights sit between the two. When my team scores an inbound case study, the first question is always which of those three it is, because that classification decides how much of the rest we have to trust.
What makes a dating affiliate case study credible?
We use a nine-field rubric internally — built from years of reading inbound case studies during onboarding — and almost no public case study scores higher than five of nine:
- GEO + sub-GEO. “Tier-1” is meaningless. Dating CR varies 3–5× between Germany on T-Mobile and Germany on Wi-Fi; “DE / T-Mobile / Android” is a disclosure, “DE” is not.
- Traffic source + zone or sub-source. “Adsterra popunder, Tier-2 zones, Android-only, mid-CPM band” is the disclosure that lets a reader assess reproducibility. “Adsterra” alone is not.
- Payout model + ratecard $ + realized $ net of scrub. SOI, DOI, PPS — and crucially, the approval rate after the advertiser’s monthly reconciliation. A revenue number that multiplies conversions by ratecard with no realized-rate disclosure is naive at best.
- Creative angle category (not the exact creative). “Astrology hook, female-first PoV, voiceover, three-second open” is a category. “We tested 12 creatives” is not.
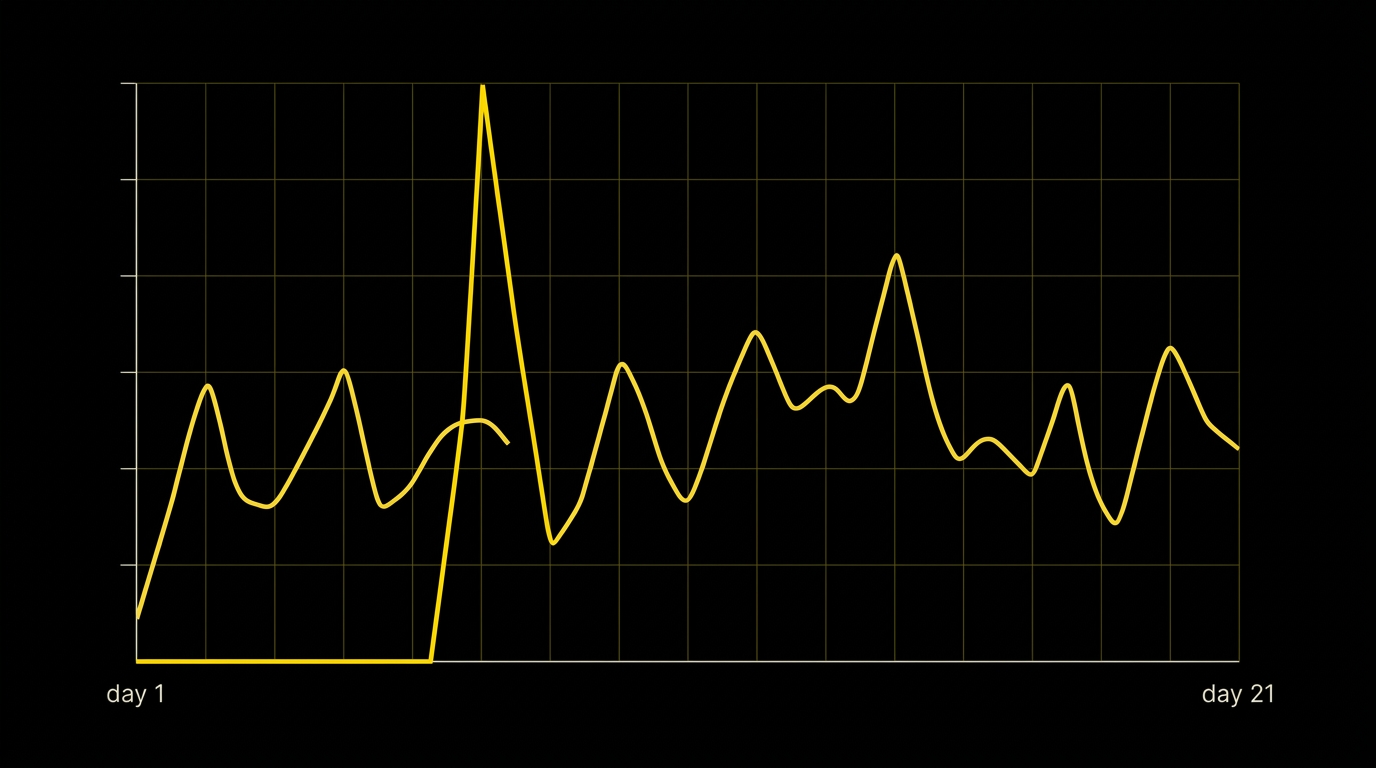
- Scale curve over time. A multi-day daily-spend-to-daily-revenue trace. A single peak-day screenshot is survivorship bias rendered as a hero number.
- Real $ banked, net of scrub, refunds and fraud claw-back. The dashboard number is not the bank-account number. Show a payment proof or a reconciled-after-30-days line.
- Attribution model. Last-click, s2s, cookie window, discrepancy with the advertiser’s CRM. With Privacy Sandbox deprecated and ITP/ATT still tightening, s2s discrepancies of 5–15 per cent against advertiser-side reconciliation are common in our network.
- What broke and how it was diagnosed. No failure section means survivorship bias or PR.
- Infrastructure TCO. Tracker, anti-detect browser, warmed-up ad accounts, proxies, agency BM fees. A “$184 profit on $33 spend” headline that omits the $200/mo anti-detect and the $400 BM rental is selling a lottery ticket priced as a strategy.
Seven of nine is rare and worth a long read. Three or fewer is marketing — close the tab.
Why is the realized payout almost always lower than the ratecard?

Because dating advertisers scrub. They retroactively disqualify a portion of paid conversions during monthly reconciliation — for reasons ranging from “the user never confirmed the email” through “the lead matched a fraud signature” to, in less reputable corners, “we ran a margin test”. The AffiliateFix thread “Shave in affiliate marketing: who, where, how?” started by Vimmy on 22 August 2023 [6] catalogues the detection signals — sharp drops in approval rate, mismatches between affiliate-side and third-party trackers, abrupt conversion declines while traffic stays flat. Community consensus across that thread and the older scrub-101 discussions [7][8]: shaving is real but unevenly distributed, and the realized rate is the only number that matters to the affiliate’s P&L.
Our ops team’s observation, not a formal export: roughly half of publisher-supplied case studies during Datify onboarding omit scrub-rate disclosure entirely, which is why we run a standard 14-day reconciliation hold on first offers regardless of claimed history elsewhere. That isn’t a stat I can export from a SQL table — it is what shows up when our managers code their notes — and I’d rather render it as a qualitative judgement than dress it up as a percentage. A case study quoting `conversions × ratecard = revenue` with no approval-rate line is making a competence claim, and the competence claim is the one we mark against.
Why are most vendor-published “474% ROI” case studies safe to skip?
Because the publisher of the case study is the traffic source being recommended. Adsterra’s blog post “ROI 474% With a Dating CPA Offer” [4] is structurally a vendor case study: Adsterra-published, Adsterra-sourced traffic, single hero ROI in the headline, no scale curve, no realized-rate line, no infrastructure TCO. PropellerAds runs a whole category page for the same genre [5]. So does AffMaven [16]. The publishing motive is lead-gen for the underlying platform — every “case study” doubles as an ad for the network or tracker hosting it. That motive does not invalidate the numbers, but it biases editorial selection toward winners and toward versions of the story that flatter the platform.
When I read one of these, I score it on the rubric and move on. Two or three of nine fields disclosed, hero ROI above 200 per cent, single screenshot, no failure section, no TCO — every one of those is a marker. The post is useful as a direction-finder (“dating push on Adsterra is the kind of thing that can work”), not as evidence the play is reproducible at the quoted ROI.
How can I tell if a dating affiliate case study is fabricated?
Four debugging moves my team uses, in order of cheapness.
First, check the author’s status on the host forum. BlackHatWorld renders moderation flags inline next to the username — “Banned for multiple accounts to game the forum” is a label we have seen on at least one widely-reshared 2024 case study (dissected below). AffiliateFix and STM Forum expose post counts, join date and reputation on the user card. A first-post user with an income headline and no follow-up history is a flag, not a source.
Second, run the affiliate’s claimed landing page through the Wayback Machine to catch edit history. A genuine lander has a deployment trail; a screenshot-quality mockup does not. Same goes for the case-study post itself — most platforms expose edit timestamps, and a post edited fifteen times in the hour after publication is usually being polished against scrutiny.
Third, cross-check the claimed lander with SimilarWeb. A case study claiming 50,000 daily visitors on a domain SimilarWeb cannot find is making a claim it cannot back.
Fourth, inspect screenshots forensically. Editing dashboard numbers via browser DevTools takes about five seconds — there is an evergreen Medium piece walking through the inspect-element technique [15]. The tell is font-rendering inconsistency: the doctored number has slightly different anti-aliasing than the surrounding numbers because the edit re-rendered with the browser’s font stack rather than the dashboard’s webfont. Zoom to 400 per cent.
How do four public dating-affiliate case studies score against the rubric?
The four examples below sit on a credibility spectrum we use internally. Author handles are anonymised; thread URLs are in the bibliography for anyone who wants to read them in full.
Operator A — BlackHatWorld, “My Experience: +557% ROI With a Dating CPA Offers!” posted 28 April 2024 [9]. Adsterra Facebook-browser CPM into a CrakRevenue dating SOI, France→multi-GEO, Android-only, $33.08 spend → $217.16 revenue, claimed 557 per cent ROI over 8–10 days. Disclosed: traffic source, offer source, broad GEO, device, $ amounts, duration. Omitted: tracker (the author argues in-thread you can optimise without one — disqualifying for attribution rigour), scale curve, approval rate, ad-account warmup. He drops in comments “I’m a member of Adsterra for a long time… that was not my first deposit” — a seasoned-account effect the headline does not account for. The post is structurally a fabrication-pattern teaching case: BHW moderation later flagged this user as “Banned – Multiple accounts to game the forum” (visible inline as of writing). Suspiciously low spend, four-figure ROI, missing scrub, missing scale curve and a banned multi-account author is the full pattern we keep pinned in Slack as the reference for what fabrication looks like. We still see it recycled into vendor newsletters in 2026. Rubric score: 2/9. Cite as negative example, never inspiration.
Operator B — affLIFT, “$66,500 Profit on Dating Offers with Push Notifications” [1]. $112,500 spend → $179,000 revenue, around 59 per cent ROI. Disclosed publicly: traffic source category (push), spend, revenue, ROI. Omitted publicly: GEO, sub-source breakdown, scale curve, attribution, scrub. The thread sits behind affLIFT’s soft-paywall; logged-in members get five to six of nine fields in our experience. The 59 per cent ROI is the kind of number a real push-dating campaign at that volume actually returns — vendor PR trends toward 200–500 per cent headlines because that converts a blog reader into a signup, not because that is what scaled campaigns earn. Rubric score: 3/9 publicly, likely 5–6/9 inside.
Operator C — affLIFT, “[Case Study] 77% ROI – German Dating Campaign with Vxcash + Email Passing Traffic (Source 7)” [2]. The title alone outscores ninety per cent of vendor case studies: specific GEO (Germany), specific advertiser network (Vxcash), specific traffic-source type (“source 7”, an explicit zone identifier). A 77 per cent ROI on tier-1 dating off niche traffic is realistic. Behind login like Operator B; public metadata alone reads 5/9.
Vendor D — Adsterra, “[Case Study] ROI 474% With a Dating CPA Offer” [4]. Adsterra-published, Adsterra-sourced traffic, Germany in some versions, hero ROI of 474 per cent. Omitted: realized-rate line, scale curve, the affiliate’s *other* campaigns that did not hit 474 per cent, infrastructure cost, attribution caveats. Useful as a direction-finder for the channel-vertical pairing; not useful as evidence the play is reproducible at that ROI. Rubric score: 3/9.
The pattern across all four: the closer the case study sits to a forum where peers ask follow-up questions, the more of the nine fields it discloses. The closer it sits to the platform whose product it recommends, the fewer.
What does the attribution gap mean for a case study’s ROI claim?
Last-click attribution over-credits the closing channel and ignores upstream touchpoints — a high ROI on push may be partly cannibalising organic and branded-search demand the affiliate did not create. The IAB Tech Lab’s ADMaP v1.0 public-comment draft from October 2024 [12] is the most useful primary on the dynamic. With Chrome’s Privacy Sandbox deprecated and Safari’s ITP and iOS ATT still tightening, the discrepancy between an affiliate’s tracker and the advertiser’s CRM is structurally widening. Our publishers running on RedTrack and ClickFlare report 5–15 per cent discrepancies versus advertiser-side reconciliation on dating offers in 2026.
If a case study’s ROI line was computed from the affiliate’s tracker dashboard, the realized ROI is almost certainly lower than the quoted number — by some fraction of that discrepancy plus the scrub. A case study that does not disclose its attribution model is betting the reader will not do this calculation. We do.
How do you write a dating affiliate case study without burning your edge?
Disclose: GEO and carrier-or-platform-segment, traffic source category and sub-source class (e.g. “push, tier-2 zones, mid-CPM band”), offer category and payout band, realized rate after monthly reconciliation, multi-day scale curve, attribution model and tracker, what broke at scale, infrastructure cost-of-running. Redact: the exact offer name (if your network will clamp down on copycats), the exact creative, the specific high-converting zone IDs.
Caveat correctly: results were on dates X–Y at volume Z; linear extrapolation is not warranted; advertiser caps can shut a play down inside a week. The publisher I respect most in our network shipped a case study at a Tier-1 conference last year that opened with “this play ran for nine weeks before the advertiser tightened the cap, here is the curve and here is the day it died” — that opening told me everything about how seriously to read the rest.
And comply. The FTC’s Endorsement Guides at 16 CFR Part 255 were last substantively revised in 2023 [14]. Any income claim a reasonable reader could take as a typical outcome requires substantiation or a “generally expected results” disclosure. The rule also requires disclosure of material connections — the offer paid you, the network gave you a referral bonus, you were given free ad credits. Most public dating case studies do not comply with this in spirit, even when the numbers are real.
How does a network like Datify actually use a supplied case study during onboarding?
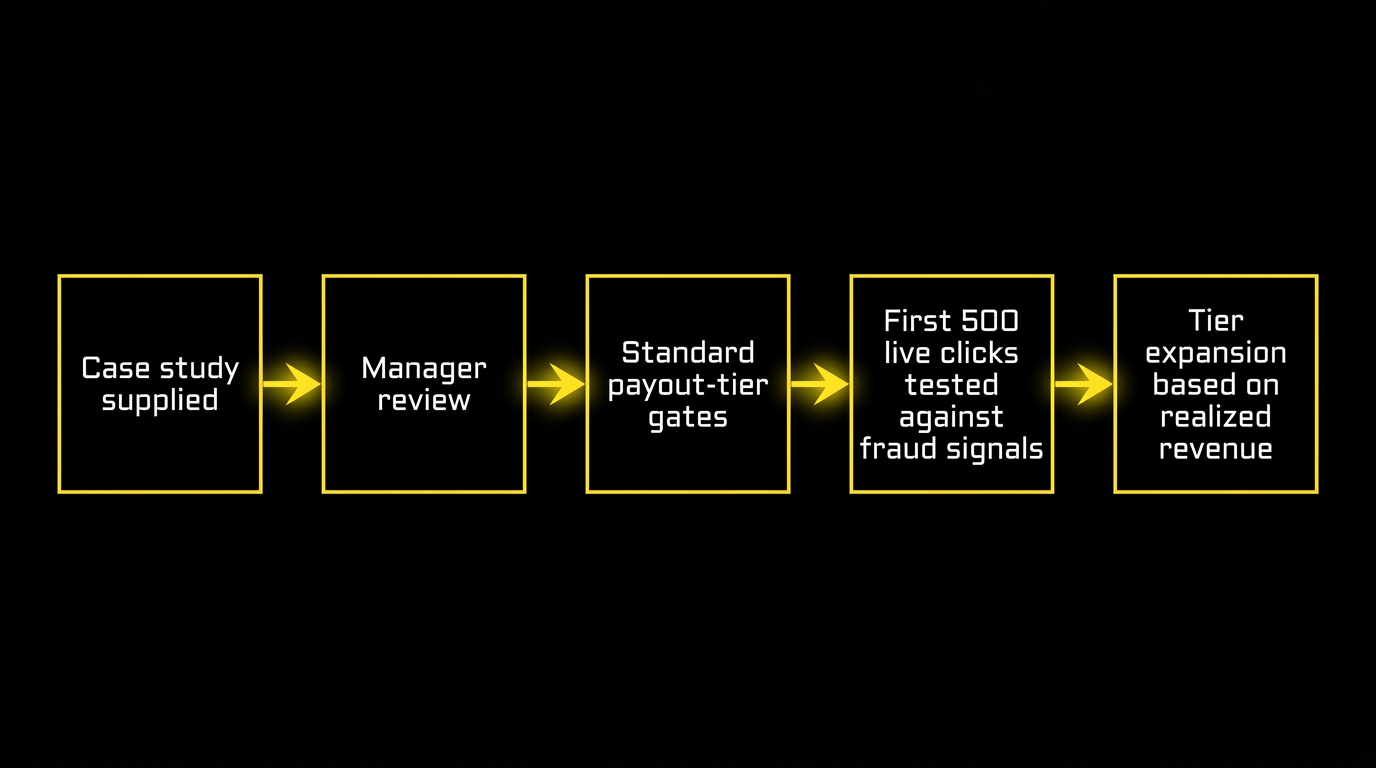
We use it as a credibility input, not a credit-extension input. That distinction matters because publishers occasionally arrive expecting a strong case study should win them a higher payout tier or a faster first payment — and at Datify it does not. Every new publisher ramps through the same payout-tier gates regardless of claimed prior $X/mo elsewhere, because tier movement is driven by realized scrub-adjusted revenue and fraud-rate *within Datify*, not by externally-claimed history.
What the case study actually buys is three minutes of my team’s attention in the onboarding interview, used as a filter. Does the publisher talk like an operator — discusses scrub, mentions the Privacy Sandbox deprecation, names a specific zone class, describes what broke last time? Or like a buyer of “make $10k/mo” courses — references a recycled BHW screenshot, quotes a headline ROI, cannot answer a follow-up about realized rate? The first is signal. The second is noise.
The next step relies on an observable platform fact: a Datify offer URL exposes multiple sub_id parameters, and routing the user’s real IP through one of them (for example sub_id_7 via the `{ip}` macro) keeps CAPI and attribution working on the real IP rather than a proxy, while sub_id_12 carries an optional upstream quality signal. Any case-study claim is testable against live performance signals on the first 500 live clicks in our system. The case study is a hypothesis; the first 500 clicks are the test. A publisher whose “97 per cent approval rate elsewhere” survives our first-week reconciliation gets tiered up. A 97 per cent that collapses to 71 once first-week reconciliation flags a chunk of it as low-quality does not — regardless of how impressively the original deck was designed.
For network selection from the publisher side, our dating affiliate programs complete guide and dating traffic sources complete guide cover the upstream selection — both worth reading before you decide which network’s case studies to take seriously.
What breaks when a successful case study tries to scale?
Three patterns. Ad-account churn TCO catches up. A “$184 profit on $33 spend” claim ignores that the operator typically burns 5–20 ad accounts to find one that ran clean — and the case study only documents the survivor. Industry consensus across operator threads on AffiliateFix and BlackHatWorld [13] is that ad-account ban and warmup cost is the dominant hidden TCO on dating CPA at scale. The break-point usually shows in week three or four, when accounts running on screenshot-day start to bin and the warmup pipeline does not refill fast enough.
The 30-day reconciliation cliff. A case study with a credible 30-day scale curve frequently disappears at month three because the advertiser’s monthly scrub catches up — realized rate drops, campaign goes from green to red without the daily-spend line moving at all. We run a 14-day reconciliation hold on first offers specifically to protect both sides of the network from this gap.
The zone-saturation cliff. A push case study on a specific tier-2 zone class saturates that zone faster than the operator expects, especially if the case study attracts copycats. Realized CPM moves up, realized CR moves down, and a 77 per cent ROI campaign becomes 12 per cent inside two weeks. The fix is to publish the *category* of the zone-source (“mid-CPM tier-2 push, Adsterra-class”) and redact the specific zone IDs — which conveniently also protects the operator’s edge.
When is a legitimate case study still misleading?
Three edge cases worth keeping in your reader’s toolkit.
Cherry-picked-day case studies. Real numbers, single peak day, scale curve hidden. The math is not fabricated; the selection is. Survivorship bias does not require fraud — it just requires editorial discretion about which day to screenshot [17]. Demand the scale curve. If it is not there, assume the peak day is the curve.
True-numbers-omitted-scrub case studies. Dashboard numbers real, scrub real, case study just doesn’t mention it. A 59 per cent ROI dashboard claim on a campaign with a 17 per cent monthly scrub is a 32 per cent realized ROI — the affiliate didn’t lie, they just didn’t disclose. We score these 4/9 or 5/9: better than vendor PR, still not reproducible.
Vendor-PR-laundering through a real operator’s handle. A working operator runs a real campaign on a vendor’s network, the vendor agrees to write it up, the operator allows their name on the post, and editorial selection of which numbers to show sits with the vendor’s marketing team. The case study reads like an operator follow-along because technically it is one — but the omissions are not the operator’s. Hallmark: the operator only ever publishes case studies on that one vendor’s blog, never on a forum where peers can ask follow-up questions. Treat as Tier-3.
Where does the FTC 2023 Endorsement Guides revision actually bite?
For the case-study *reader*: when a vendor blog post quotes an affiliate’s “$50,000/mo” claim without a “generally expected results” disclosure and without disclosing the material connection between affiliate and vendor [14]. For the *writer*: when you publish your own “I made $X” claim without that disclosure. For the network: when we run a public success story on a publisher whose numbers we cannot substantiate. We don’t — we publish anonymised patterns and aggregate observations, and when we cite an individual outcome we put the date range, GEO and substantiation note on it. Enforcement is rare in dating but not zero, and FTC attention on creator-economy income claims has trended up across 2024–2026. The compliance ask is one disclosure line. The non-compliance risk is unbounded.
What case studies are actually worth reading this year?
The reading list I would give a new publisher: the affLIFT “$66,500 Profit on Dating Offers with Push Notifications” thread for what a credible scale-volume push case study looks like [1]; the affLIFT German Vxcash thread for an operator-grade niche-traffic write-up [2]; the AdsEmpire follow-along on affLIFT for a multi-week dating follow-along with daily updates [3]; the AffiliateFix shave thread by Vimmy [6] as the canonical reference on the realized-rate gap; and the BlackHatWorld “+557% ROI” thread [9] as the canonical *negative* example — read it to internalise what the fabrication pattern looks like.
What I would not read: any case study where publisher and traffic source are the same company, any post under 500 words with a four-digit-ROI headline, and anything cross-posted between AffMaven, Mobidea, AffVerse, WeCanTrack and Cometly that traces back to a single primary none of the aggregators link to.
For related operational reading, our best affiliate marketing trackers 2026 and SEO for affiliate marketing complete guide cover the tracker- and discovery-side context that determines how repeatable any case study actually is. Future case-study teardowns will land in the case studies archive.
FAQ
Q: What is a dating affiliate case study?
A: A published account of how an operator drove paid traffic to a dating CPA, smartlink, or revshare offer and what it returned after scrub, refunds and infrastructure cost. In 2026 the term covers three artefacts — operator follow-alongs on closed forums, vendor-published “success” posts on ad-network blogs, and network partner spotlights — and only the first reliably contains enough disclosure to be reproducible.
Q: How do I score a dating affiliate case study quickly?
A: Count how many of the nine fields it discloses: GEO + sub-GEO, traffic source + zone, payout model + realized rate, creative angle category, multi-day scale curve, real $ banked, attribution model, what broke, and infrastructure TCO. Seven of nine is rare and worth a careful read. Five is operator-grade. Three or fewer is marketing — close the tab. Vendor-published posts almost never score above three; forum follow-alongs typically land between four and seven.
Q: Why does the realized payout differ from the ratecard?
A: Because the advertiser scrubs — retroactively disqualifies a portion of paid conversions during monthly reconciliation, for reasons ranging from email-confirmation failures and fraud signatures to, in less reputable corners, margin testing. The realized rate is the only number that matters to the affiliate’s P&L. A case study quoting conversions × ratecard with no realized-rate line is making an implicit competence claim that should be marked against.
Q: How can I tell if an income screenshot in a case study is fabricated?
A: Inspect-element edits on dashboard numbers take seconds — there is an evergreen Medium piece walking through the technique. The forensic tell is font-rendering inconsistency: the doctored number has slightly different anti-aliasing because the inspect-element edit re-rendered it with the browser’s font stack rather than the dashboard’s webfont. Zoom to 400 per cent. Pair this with checking the author’s moderation status and the post’s edit history.
Q: Does the BHW “+557% ROI” thread count as a credible case study?
A: No. The author of that 2024 thread was later flagged by BlackHatWorld moderation as banned for multiple accounts to game the forum, and the post itself scores 2/9 on our rubric — no scale curve, no realized rate, no tracker, no failure section. Suspiciously low spend, four-figure-ROI headline and a multi-account-banned author together form the canonical fabrication pattern. We keep it pinned in Slack as the example to recognise, not inspiration to replicate.
Q: How does Datify use case studies during publisher onboarding?
A: As a credibility input, not a credit-extension input. The supplied case study buys three minutes of our manager’s attention as an interview filter — we listen for whether the publisher talks like an operator or like a course-buyer. Every new publisher ramps through the same payout-tier gates regardless of claimed prior earnings, because tier movement is driven by realized scrub-adjusted revenue and fraud-rate inside Datify. The first 500 live clicks are the test.
Q: Do FTC rules apply to a dating affiliate case study published outside the US?
A: If a US audience is in scope, yes. The FTC’s Endorsement Guides at 16 CFR Part 255, last substantively revised in 2023, apply to any income claim a reasonable US reader could take as a typical outcome — regardless of where the affiliate or network is domiciled. The compliance ask is small (a “generally expected results” disclosure plus a material-connection disclosure) and the enforcement risk has trended up, not down, across the creator economy.
Q: What’s the cheapest way to validate someone else’s case study claim?
A: Four moves: check the author’s moderation status on the host forum, run the claimed lander through the Wayback Machine, cross-check the lander on SimilarWeb, and zoom screenshots to 400 per cent for font-rendering inconsistency around the headline number. Total time per case study: about five minutes. If it survives all four, the rubric score is worth taking at face value.
Sources
1. affLIFT, “$66,500 Profit on Dating Offers with Push Notifications (FREE Case Study)” — https://afflift.com/f/articles/66500-profit-on-dating-offers-with-push-notifications-free-case-study.170/ 2. affLIFT, “[CASE STUDY] 77% ROI – German Dating Campaign with Vxcash + Email Passing Traffic (Source 7)” — https://afflift.com/f/threads/case-study-77-roi-%E2%80%93-german-dating-campaign-with-vxcash-email-passing-traffic-source-7.14918/ 3. affLIFT, “AdsEmpire Follow Along you’ve been waiting for! (Dating)” — https://afflift.com/f/threads/adsempire-follow-along-youve-been-waiting-for-dating.9257/ 4. Adsterra Blog (vendor PR, used as laundered-case-study example only), “[Case Study] ROI 474% With a Dating CPA Offer” — https://adsterra.com/blog/case-study-roi-474-with-a-dating-cpa-offer/ 5. PropellerAds Blog (vendor category page, used as pattern example only), “Social and Mainstream Dating Affiliate Case Studies” — https://propellerads.com/blog/category/learn/case-studies/dating/ 6. AffiliateFix, “Shave in affiliate marketing: who, where, how?” thread by Vimmy, 22 August 2023 — https://www.affiliatefix.com/threads/shave-in-affiliate-marketing-who-where-how.174439/ 7. AffiliateFix, “Why Do Advertisers Scrub Leads? The Basics About Scrubbing!” — https://www.affiliatefix.com/threads/why-do-advertisers-scrub-leads-the-basics-about-scrubbing.3238/ 8. Warrior Forum, “[Why Do] Advertisers Scrub Leads? Understand The Basics About Scrubbing!” — https://www.warriorforum.com/ad-networks-cpm-cpl-display/731113-why-do-advertisers-scrub-leads-understand-basics-about-scrubbing.html 9. BlackHatWorld, “My Experience: +557% ROI With a Dating CPA Offers!” by ad2007 (status: Banned – Multiple accounts to game the forum), 28 April 2024 — https://www.blackhatworld.com/seo/my-experience-557-roi-with-a-dating-cpa-offers.1595151/ 10. affLIFT, “What Traffic Works Best for Dating Offers in 2025? Advery Experts Share Their Top Picks” (2025) — https://afflift.com/f/articles/what-traffic-works-best-for-dating-offers-in-2025-advery-experts-share-their-top-picks.503/ 11. Advidi Blog (used for vertical context only), “The Dating Vertical in 2025: What’s Hot And What’s Not For Affiliate Marketers” (2025) — https://advidi.com/blog/dating-trends-in-2025/ 12. IAB Tech Lab, “ADMaP: Attribution Data Matching Protocol — Version 1.0” (public comment release, October 2024) — https://iabtechlab.com/wp-content/uploads/2024/10/ADMAP-Version-1.0-for-PUBLIC-COMMENT.pdf 13. AffiliateFix dating-CPA-network tag index (forum-wide context on ad-account churn TCO) — https://www.affiliatefix.com/tags/dating-cpa-network/ 14. FTC, “16 CFR Part 255 — Guides Concerning Use of Endorsements and Testimonials in Advertising” (current eCFR text, last substantively revised 2023) — https://www.ecfr.gov/current/title-16/chapter-I/subchapter-B/part-255 15. Medium, “Creating Fake Earnings/Views Screenshots in Just 5 Seconds — Scammers’ Dirty Little Secret Exposed” — https://medium.com/@jamiebrandon02/creating-fake-earnings-views-screenshots-in-just-5-seconds-scammers-dirty-little-secret-exposed-43c317201ffb 16. AffMaven (used as case-study-aggregator pattern example only), “How We Made $12,500 Promoting AI Dating Offers: Case Study” — https://affmaven.com/ai-dating-offers-case-study/ 17. Alex Denning, “Survivorship bias and case studies that make everything look easy” — https://www.alexdenning.com/survivorship-case-studies-easy/